
データベース型サイトはURLが自動生成され、一覧・詳細・ファセットといったテンプレートが指数関数的に増殖します。SEOでは「何を作るか」以上に「何をインデックスさせ、何を排除するか」の設計が勝敗を分けます。本記事は社内ナレッジで磨いた「クロール最適化→インデックス→ランキング」の順序を軸に、IA/URL/テンプレとログ運用を連動させる具体手順を、EC・不動産・求人・グルメなどDB型の現場課題に即して解説します。

データベース型サイトとは?記事型との違いとSEO特性
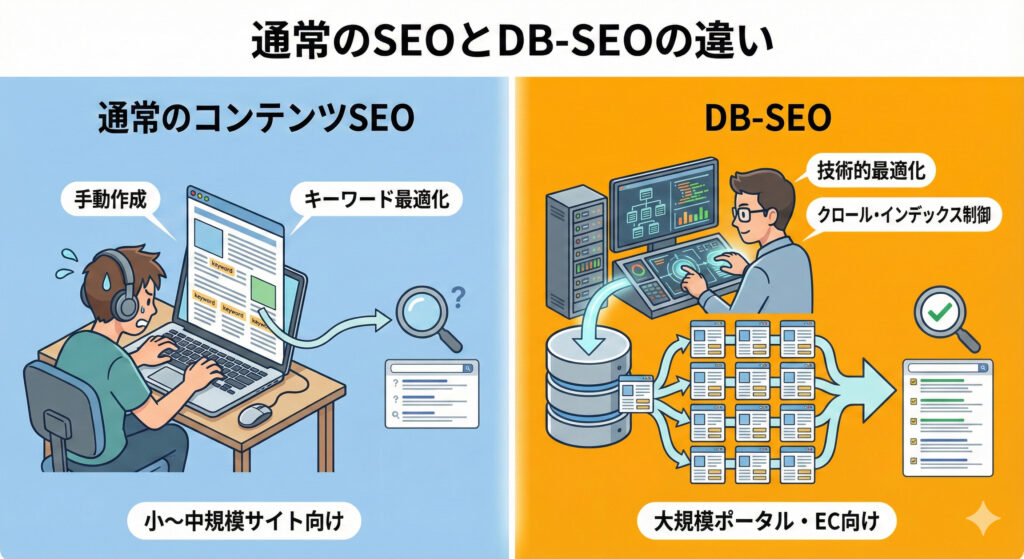
DB型は設計と運用が品質を決めます。URLの自動生成とテンプレの量産により、重複・薄いページ・パラメータ氾濫が起こりやすく、ボトルネックはクロールとインデックスの最適化にあります。KPIは「クロール→インデックス→ランキング」の順で設計・改善します。
DB型の代表例(EC・不動産・求人・グルメ)と共通課題
ECサイトではソートや在庫、有無や色違いなどのバリエーションがURLを膨張させ、同一集合の重複一覧や在庫切れ詳細の扱いがKPIに直結します。不動産やグルメではエリア×カテゴリ×属性の組合せが爆発し、0件リストが量産されやすいのが特徴です。求人は募集終了や差し替えの寿命管理が重要で、JobPostingのvalidThrough更新やステータスの整合性維持が不可欠です。いずれも本質は「不要クロールの抑制」と「必要URLへのクロール頻度確保」で、生ログ分析によりパラメータや静的資産への過剰クロールを可視化し、継続的に削ることでクロールバジェットを重要URLへ振り向けられます。
https://ny-marketing.co.jp/blog/crawl/crawler_analyze/
記事型との根本差分:URL生成、テンプレート、拡張性がSEOに与える影響
記事型は手作り・少数精鋭で品質を担保しやすいのに対し、DB型はテンプレ量産により評価の分散が起きやすく、正規化と内部リンクの集中設計が前提になります。URLパラメータは順序や許可リストで正規化し、スラッグの命名規則を運用ルール化して、将来の拡張時に重複や無限生成を防ぎます。構造化データやパンくず、ハブページなどサイト全体のランキング要素はテンプレートで標準実装し、全ページ型で一貫して効く「全体最適」を仕込みます。これによりページ単体最適の積み重ねでは到達できないスケール効率を実現できます。
検索意図に合う情報アーキテクチャとディレクトリ階層の重要性
DB型の氾濫を抑える第一の砦は、エリア×カテゴリ×属性をMECEに分解した情報アーキテクチャです。階層は原則3層を目安に浅く保ち、同一集合は代表URLへ正規化して重複集合を作らないのが社内ベストプラクティスです。パンくずはディレクトリの写像ではなく「ユーザーの辿る経路」を表すリンク構造で設計し、JSON-LDのBreadcrumbListを実装して文脈を強化します。こうしたIA設計はクロール効率を上げるだけでなく、ユーザーの回遊導線を明確にし、ランキング要素となる行動指標にも寄与します。
大規模サイトは「まずクロール最適化」:効果の出る順序とKPI
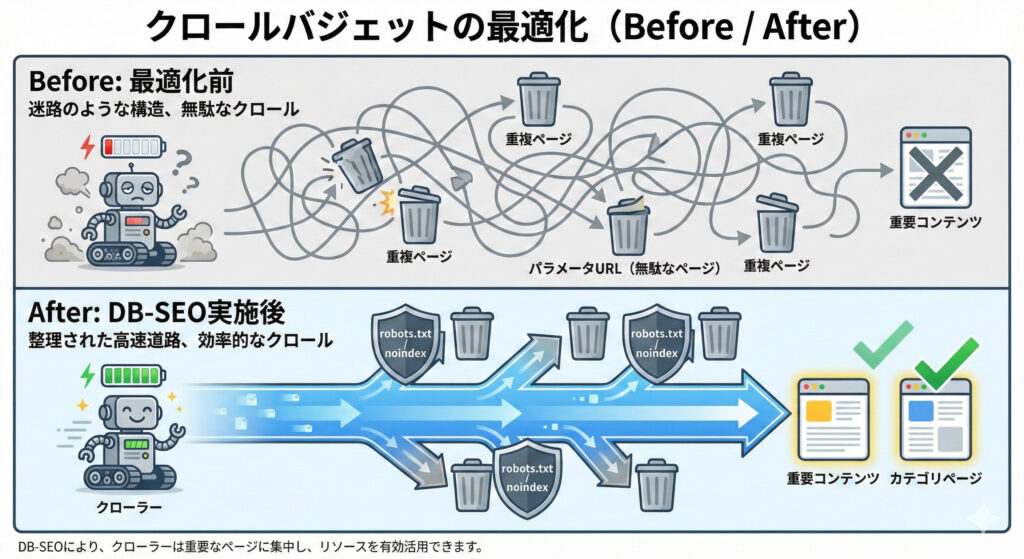
効果の出る順は「クロール→インデックス→ランキング」。被クロール率と必要/不要クロール比、重要URLのクロール頻度をKPI化し、月次でログを回して改善します。無駄なパラメータや静的資産への過剰クロールを特定・遮断します。
クロール最適化→インデックス最適化→ランキング最適化の手順
最初に生ログで不要クロールの発生源を特定し、robots.txtや内部リンクの改修で抑制します。次にサイトマップ分割とハブ/パンくず/関連リンクで重要URLの発見性を最大化し、インデックス率を底上げします。最後にタイトルとテンプレテキスト、横断内部リンクを最適化して、CTRと順位を横展開で引き上げます。この順番は、ボトルネックであるクロールの無駄を先に削ぎ落とすことで、後続の施策が効率よく成果に繋がるからです。引用の通り、当社は「クロール→インデックス→ランキング」の順で支援を標準化しています。
https://ny-marketing.co.jp/blog/crawl/google-crawler/
クロールKPI設計:被クロール率/必要対不要クロール比/重要URLのクロール頻度
被クロール率は「重要URLへのクロール÷総クロール」で定義し、月次の改善トレンドで管理します。必要:不要クロール比は一覧・詳細・ハブを必要、パラメータ・0件・重複を不要と定義し、不要比率の継続削減を目標に置きます。重要URL(一覧/詳細)の月間クロール頻度は閾値を定め、下回る集合には内部リンクの強化とサイトマップによる再発見促進を使い分けます。ログ・GSC・サイトマップの3点を同一ダッシュボードで可視化し、6カ月の改善サイクルで安定化させるのが定石です。
サーバーログでのクロール分析手順と見るべき指標
まず1カ月分の生ログを取得し、User-AgentでGooglebotを抽出したうえで、URLパターン単位(一覧/詳細/param/静的)に集計します。指標は、重要URLのクロール回数、不要パラメータ比率、5xx/404の発生、CSS/JS/画像など静的資産への過剰クロールです。ログ分析ツール定期自動集計し、施策→検証のPDCAを6カ月連続で回すことを推奨します。これにより不要領域のクロール削減と重要URLの頻度増が両輪で進み、検出-未登録の抑制に繋がります。
robots.txt・meta robots・HTTPヘッダnoindexの使い分け
robots.txtはクロール拒否・効率化に用い、会員制エリアやテスト環境、無限増殖するパラメータ群を対象にします。検索結果からの除外はmeta robots noindex、PDF等のバイナリはHTTPヘッダのX-Robots-Tagで実装します。なおnoindexとcanonicalの併用は矛盾を生みNGです。正規化はcanonical、除外はnoindexと役割を分離し、サイトマップや内部リンクも正規URLに揃えることで信号を統一します。
参考:https://developers.google.com/search/docs/crawling-indexing/robots-meta-tag
参考:https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls
不要クロールの発見と抑制
ログでsortやpage_size、trackingといったパラメータへの高頻度クロールを発見し、robots.txtのDisallowで一括抑制します。同時に内部リンクから不要パラメータを付与しないテンプレ化が重要で、とくにページネーションへのパラメータ引き継ぎは重複と無限化の温床です。0件一覧や重複一覧は露出自体を避け、UI上もリンクを削除またはグレーアウトしてクローラーパスを遮断します。これにより必要:不要クロール比の改善が実感でき、重要URLの再訪頻度が底上げされます。
内部検索結果・並び替え・ページサイズ変更などパラメータ制御
内部検索結果は原則noindexとし、トップクエリのみ編集・固定化したランディングを用意する場合に限り例外でindexを許容します。sort/page_size/表示切替などはnoindexに加え、canonicalを正規URLへ指すのが基本で、クロール自体はrobots.txtで最小限に抑えます。パラメータの順序正規化と許可リスト化を実装し、同一内容の重複URLが増殖しない仕組みをコード側に持たせて運用ミスも防止します。
空データ・重複一覧の検知とブロック方針
0件ページは生成しない・リンク露出しないが第一原則です。やむを得ず生成された場合はnoindexとし、サイトマップから除外します。同一集合の複数一覧が存在する場合は代表URLへcanonicalを統一し、根本的にはファセット設計で未然に防ぎます。ログでは0件/重複へのクロール比率をKPI化し、月次で削減幅を追う運用に落とし込みます。これによりクローラーパスが重要URLへ集中し、インデックス効率と更新の反映速度が安定します。
インデックス最適化:必要なページを確実に登録させる
GSCカバレッジ、サイトマップ到達率、ログ被クロール状況を統合監視し、「検出-インデックス未登録」を原因別に切り分けます。発見不足の改善が先行すべきケースも多い点に注意します。
インデックス数のモニタリング(Search Console/サイトマップ/ログ)
GSCでは有効/除外の推移と「除外のうち意図的noindex比率」をKPI化し、意図と結果のギャップを管理します。サイトマップは送信URL数とインデックス済み数の到達率を週次で確認し、到達が低い集合に対しては内部リンクやlastmod更新で再発見性を強化します。ログでは重要URLのクロール頻度が閾値を下回らないかを併せて評価し、発見不足が疑われる場合はクロール最適化に立ち戻ることが肝要です。
参考: https://support.google.com/webmasters/answer/7440203?hl=ja
参考: https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap
サイトマップ分割設計(上限・優先度・更新頻度)
XMLサイトマップは1ファイルあたり最大50,000URL・非圧縮50MBが上限のため、超過時は分割しsitemap indexで束ねます。ページタイプ(詳細/一覧/特集/言語別)で分割し、lastmodを正確に更新して優先的に再クロールさせます。低品質・noindex・重複URLは掲載禁止とし、重要URLは更新頻度を高めて反映を早めます。運用では生成スクリプトの健全性を監視し、差分更新とフル再生成の切替基準を定めておくと事故を防げます。
参考: https://developers.google.com/search/docs/crawling-indexing/sitemaps/large-sitemaps
未登録の原因別対処(品質不足/発見不足/ブロック設定の誤り)
品質不足なら薄い一覧を削除・統合または独自テキストを増補し、詳細は画像/レビュー/固有属性と構造化データを充足させます。発見不足にはサイトマップ送信とハブ/パンくず/関連リンクからの導線追加で対応します。ブロック誤りはrobots.txt・meta robots・X-Robots-Tagの過剰設定を見直し、正規URLに内部リンクとサイトマップを統一して信号を一本化します。これらをダッシュボードで原因別に管理し、再クロール後のステータス改善を確認します。
canonicalとnoindexの正しい使い分けと落とし穴
canonicalは評価を代表URLに集中させる正規化のためのヒントで、noindexは検索結果からの除外指示です。両者の併用は矛盾を生み、Googleの最終判断を混乱させるためNGです。パラメータ派生は原則代表URLへcanonicalを統一し、品質が閾値を下回る派生はnoindexで除外するなど、役割を明確に分担します。サイトマップや内部リンクも必ず正規URLに統一し、信号の一貫性で誤判定を防ぎます。
参考: https://developers.google.com/search/docs/crawling-indexing/consolidate-duplicate-urls
ファセットナビゲーションの正解パターン(代表/詳細/組合せの扱い)
需要×件数が十分な代表ファセットのみindexを許容し、複合や末端はnoindex+canonicalで代表へ寄せます。0件ファセットは露出しない生成ポリシーとし、内部リンクから到達不可にしてクロール浪費を排除します。UIではチェックボックスや並び替えのパラメータをページネーションに引き継がず、一覧の代表URLから各下位へ明確な導線を敷くことで、クロールの自己増殖と重複の無限化を防ぎます。
内部リンク設計で評価を循環させる
ハブ(カテゴリ/地域)→一覧→詳細の三層導線を明確にし、重要URLへPageRankを集中させます。孤立ページをゼロにするため、GSCやクローラーツールで到達経路を定期検出し是正します。人気・新着・関連の横断導線をテンプレートで設計し、回遊と再クロールの頻度を高めます。ユーザーの行動文脈に沿ったリンクは、CTRの改善にも波及し、クロール頻度→インデックス→ランキングの好循環を強めます。
パンくず・関連リンク・ハブページ・人気/新着の最適化
パンくずは「ユーザーが辿る経路」のリンク構造で設計し、JSON-LDのBreadcrumbListを実装して検索エンジンに文脈を伝えます。関連リンクは同カテゴリ・近傍エリア・類似属性など関連性の高い集合に限定し、数ではなく質を重視します。ハブは検索ボリュームが大きいディメンションを優先配置し、新着・人気のモジュールで再訪・再クロールを促す構成にします。テンプレ化して全ページに浸透させると効果が雪だるま式に積み上がります。
ディレクトリ構造とURL設計:DB型サイト固有の勝ちパターン
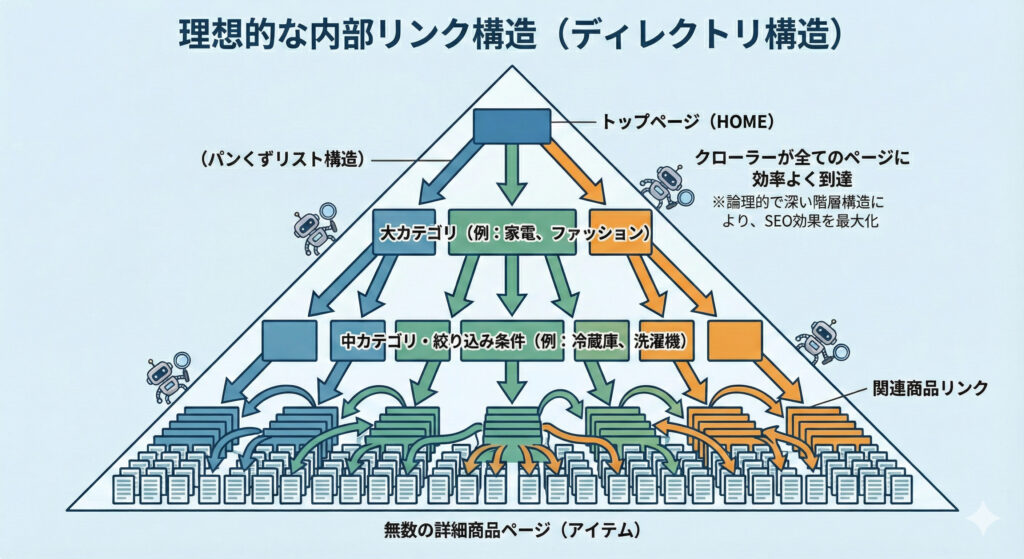
「エリア×カテゴリ×属性」をMECEに分解し、スラッグは英小文字・ハイフンで正規化します。階層は浅く、末尾スラッシュ/大文字小文字/トレイルを全サイトで統一します。
エリア×カテゴリ×属性の階層とスラッグ命名規則
/area/cat/attr/ の固定順で、英小文字とハイフン区切りを採用し、日本語スラッグは原則避けます。属性は代表のみスラッグ化し、細分はパラメータ扱いとした上でnoindexで制御します。多言語・多地域の展開を見据え、将来的なhreflang運用を前提にサブディレクトリで分離可能な設計にしておくと拡張の副作用が最小化します。命名規則と順序正規化は開発・運用ドキュメントに落として、リリースレビューのチェック項目に組み込むのが事故防止の近道です。
階層の深さの上限と浅い階層を保つための正規化
4層を超える深層化は内部リンク到達性とクロール効率を悪化させるため、統合や別軸ハブで浅層化します。末尾スラッシュ、index.htmlの扱い、大文字小文字、トレイリングスラッシュの統一は社内ガイドで必須とし、リダイレクト方針をサーバー設定で強制します。導線はディレクトリ階層に縛られず、ハブ・パンくず・関連で柔軟に補完することで、浅い階層ながら情報密度の高いサイト体験を提供できます。
ページタイプ別テンプレート最適化(一覧/詳細/タグ/特集)
一覧は「意図×地域×属性」を見出し・導入・本文ブロックで明示し、内部リンクとItemListの構造化を標準実装します。詳細は固有情報の網羅、関連導線の強化、Product/JobPosting/Place等の構造化データを必須化します。タグ/特集は需要と差別化の基準を満たさないものはnoindexにし、満たすものはハブとして育成します。これらをテンプレレベルで実装することで、新規生成ページでも品質の底上げが自動で効きます。
ページネーション設計と検索意図の両立
ページネーションは各ページを自己カノニカルとし、noindex/nofollowは使いません。Googleはrel prev/nextを順位シグナルとして利用していないため、HTMLの前後ページリンクを明示し、代表URLからの導線を明確にします。絞り込みパラメータをページネーションへ引き継がないようにし、同一集合の重複や無限化を防ぎます。ユーザーには「上位の代表一覧」「人気」「関連」で回遊を促し、末尾ページに到達せずとも意思決定できる情報設計を意識します。
参考: https://searchengineland.com/pagination-seo-what-you-need-to-know-453707
多言語・多地域対応のhreflangと重複回避
言語/地域ごとに必ず別URLを用意し、UI切替のみで同一URLに集約する設計は避けます。各バリエーションの相互にhreflangを実装し、x-defaultも適切に設定します。サイトマップでの一括宣言は運用上有効で、大規模サイトでは更新漏れの防止に役立ちます。翻訳品質はメタ/タイトルの長さ制約も含めて各言語に最適化し、直訳での薄いページ化を防ぐ体制を敷きます。
参考: https://developers.google.com/search/docs/advanced/crawling/localized-versions
コンテンツ品質と重複対策:薄いページを生まない運用
品質スコアリング基準を決め、一覧/詳細で自動検知し改善・除外を回します。空や空に近いページは公開せず、noindexと代替導線をテンプレで用意します。
品質スコアリングの基準化と自動モニタリング
一覧は件数、独自テキスト量、内部リンク密度、CTRを組み合わせたスコアで評価し、閾値未満はnoindexまたは統合を検討します。詳細は固有属性の充実度、画像点数、レビュー有無、更新鮮度、構造化データの充足を数値化し、流入とインデックス状態との相関をダッシュボードで可視化します。スコア×流入×インデックスの三次元で監視し、施策の優先度付けを機械的に回すことで、人的工数を価値の高い集合へ集中できます。
在庫切れ・募集終了・売止めページの扱い
恒久終了は代替が明確なら301で類似在庫や後継商品へ統合し、代替が乏しい場合はページを存置して「終了明示」と代替提案を強化します。一時欠品はページを維持し、ProductのavailabilityでOutOfStock等を構造化します。求人は募集終了時にvalidThroughを過去日に更新し、検索流入が不要ならnoindexも選択肢です。どの選択でもユーザーの期待値管理を最優先に、内部リンクと構造化の整合性を保ちます。
参考: https://developers.google.com/search/docs/appearance/structured-data/product , https://developers.google.com/search/docs/appearance/structured-data/job-posting
301/代替提案/内部リンク/構造化データ更新の判断基準
301かページを残すかは流入・被リンク・類似在庫の有無で判定します。ページを残す場合は関連カテゴリ・類似品・人気・新着への内部リンクを強化し、ユーザーの離脱を防ぎます。構造化データ(Product/JobPosting)はステータス・価格・期日を最新状態へ更新し、検索結果での齟齬を避けます。表面だけのnoindexではなく、ユーザーファーストの導線とデータ整合性を両立させることで、長期的な評価低下を防げます。
参考: https://developers.google.com/search/docs/appearance/structured-data/product、https://developers.google.com/search/docs/appearance/structured-data/job-posting
自動生成テキストの品質担保とE-E-A-Tの実装
テンプレートには独自データや専門コメント、地域統計を織り込み、同質化を避けます。著者・監修・運営情報を明示し、更新履歴と外部参照を適切に付与してE-E-A-Tのシグナルを補強します。自動生成の監視KPIとして重複率・類似度・滞在・直帰を持ち、閾値でテンプレ修正をトリガーする運用を設けます。これによりスケールしながら差別化を維持し、質の劣化を早期に検知できます。
構造化データで可視性を最大化
一覧はItemList/CollectionPage、詳細はProduct/JobPosting/Placeなどを適切に選択し、JSON-LDで全ページ型に標準実装します。GSCでエラーを常時監視します。
一覧ページ:ItemList/CollectionPageの実装ポイント
ItemListではListItemのposition/name/urlを正確に出力し、サムネイルや要約の体裁をテンプレで統一します。パンくず(BreadcrumbList)と併用し、カテゴリ・地域などの文脈を明示することで、検索結果での理解を助けます。0件一覧には構造化を出さず露出も抑え、クロールと品質の双方を保全します。検証は公開前後で構造化テストを運用フロー化し、警告やエラーをゼロで維持します。
詳細ページ:Product/JobPosting/Placeなどスキーマの使い分け
ECはProductでprice・availability・brand等を必須化し、求人はJobPostingでhiringOrganizationやvalidThroughを正確に管理します。店舗/施設はPlaceでaddress・geo・openingHoursを実装してローカル意図に応えます。リッチリザルトの要件を満たしつつ、実態と齟齬のない更新を徹底し、サイト全体の信頼性を損なわないデータ運用を行います。
参考: https://developers.google.com/search/docs/appearance/structured-data/product 、https://developers.google.com/search/docs/appearance/structured-data/job-posting
リッチリザルト獲得とフィード連携の補助施策
GSCのリッチリザルトレポートでエラー/警告を常時ゼロに保ち、変化があれば即時にテンプレ修正を反映します。商品・求人はGoogle Merchant CenterやJob配信などのフィード連携を併用し、再クロールを促進して最新性を担保します。公開前には構造化データ検証ツールで必ずテストし、デプロイゲートの必須チェックに組み込むのが失敗を防ぐ鉄則です。
内部リンクとタイトル設計:評価の循環とクリック率を同時に改善
ハブ→一覧→詳細の階層と横断リンクを設計し孤立を排除します。テンプレごとに「意図×差別化」をタイトル/見出しへ反映し、CTRを底上げします。
サイト全体の内部リンク設計(階層・横断・回遊)
トップページは検索ボリュームの大きいディメンションに深い導線を敷き、一覧は関連・下位条件へ、詳細は上位・類似へ戻る循環を明確にします。共通ナビ(ヘッダー/フッター/サイド)はユーザビリティ重視で厳選し、被リンクが集まりやすいハブを意図的に設計して評価の循環を強めます。行動計測で回遊のボトルネックを洗い出し、リンク位置とテキストを継続的に磨きます。
テンプレート別のタイトル/見出し設計でCTRと関連性を両立
一覧は「エリア×カテゴリ×主要属性|件数/強み」を前方配置し、ユーザーの意図に即した判断材料を早期提示します。詳細は固有名と主要USP、在庫/価格/勤務地など意思決定情報を先頭に置きます。特集/タグは検索意図と差別化ポイントを見出しで明示し、単なる集合ではなく「選ばれた理由」を伝えることでCTRを継続改善します。ABテストで前方語の最適化を行い、勝ちパターンをテンプレへ展開します。
ログ起点のクロール分析ツールの活用
10万ページ超では生ログ解析が必須です。不要クロール削減と重要URLの頻度増を両輪で実行し、月次ダッシュボード化で継続チューニングします。弊社NYマーケティング株式会社では生ログ分析のスポット調査、もしくはツール販売をしています。
▽ツールについて詳しくはこちら
https://ny-marketing.co.jp/blog/crawl/crawler_analyze/
必要URLのクロール頻度を高めるための優先度設計
サイトマップのlastmod更新、ハブからの直リンク、人気・新着露出を連動させ、クローラーパスを重要URLへ誘導します。古い/低回遊の重要URLはハブからの再リンクで再活性化し、ログで頻度の回復を確認します。これらを月次で再評価し、GSCの「検出-未登録」やインデックス到達率の改善とセットで進捗を管理します。
不要URLのクロール削減(検出→ブロック→再評価)
まずログでparam/0件/静的資産への過剰比率を抽出し、robots.txt、内部リンク改修、noindex、canonicalの多層防御でブロックします。翌月ログで改善幅をKPI化し、残存している経路を深掘りして追加対策を打ちます。ブロックは「入口(リンク)」「ルール(robots)」「信号(meta/canonical)」の三位一体で行い、いずれかが抜け道にならないよう網を張ります。
10万ページ超サイトでの実施手順(現状把握→施策→再クロール確認)
現状把握ではログ(1カ月)、カバレッジ、サイトマップ到達率を基準化します。施策はブロック/導線/サイトマップ/テンプレ改修をスプリントで実装し、デプロイ後に再クロールを確認します。GSCの「検出-未登録」減少と有効ページ増、重要URLへのクロール頻度上昇が揃えば正しく回り始めています。以降はKPIを月次で監視し、閾値を割る集合に対策を重点配分します。
運用ダッシュボードと改善サイクル
月次で「クロール/インデックス/カバレッジ/ランキング/CTR」を統合監視し、テンプレABと内部リンク調整を計画的に回します。外部リンクは特集・統計のデータ資産化で獲得します。
月次モニタリング:カバレッジ/クロール/インデックス/ランキングの統合
有効/除外、検出-未登録、意図的noindexの割合、サイトマップ到達率を横並びで見ます。重要URLのクロール頻度と順位×CTRの相関を可視化し、機会損失の大きい集合に優先投資します。これらを同一ダッシュボードに統合し、担当横断で共通言語を持つことで改善サイクルの速度と精度が上がります。
A/Bテストでのタイトル・内部リンク最適化
タイトル/見出しの前方語配置と差別化表現をAB検証し、勝ちパターンをテンプレへ反映して全ページへ波及させます。ハブ/一覧のリンク配置と数も行動計測で最適点を同定し、クリック熱量の高い位置へ再配置します。テストは季節変動の影響を避けるため2〜4週間の同時配信を基本とし、統計的有意性の基準を事前定義します。
外部リンク獲得とデータ資産化(特集・レポート・統計公開)
地域/カテゴリ統計、ランキング、ベンチマークを定期公開し、ナチュラルリンクを獲得します。PRカレンダーを用いて季節・話題に合った特集を量産し、SNSとメディア露出で波及させます。DB型の強みである一次データを編集価値へ昇華させ、継続的に引用される資産を育てることが、外部リンクの最小コスト獲得に繋がります。
参考: https://ny-marketing.co.jp/blog/seo-outside/how-to-get-backlink/#index_id3
ページタイプ別チェックリスト(実務向け)
一覧はインデックス許可条件とItemList必須、詳細は構造化と代替導線を必須に。タグ/特集は価値基準に満たなければnoindexで管理します。
一覧ページ:インデックス許可条件/重複統合/構造化/ページネーション
需要×件数が閾値を超える集合のみindexを許容し、その他はnoindex+canonicalで代表URLへ寄せます。ItemListとパンくずは必須、ページネーションは自己カノニカルでparam非引継ぎを徹底します。見出しと導入で「意図×地域×属性」を明示し、関連・下位条件・人気/新着への導線で回遊性を担保します。検証はGSCの到達率とCTRで併走評価します。
詳細ページ:必須要素/類似品導線/在庫・更新時の扱い
固有情報、画像、レビュー、構造化(Product/JobPosting/Place)を満たし、上位カテゴリ・類似・人気への導線で回遊を促します。在庫や募集状態はページ内と構造化の双方で明示し、更新時はサイトマップのlastmodも反映します。恒久終了は301、暫定は存置+代替提案でユーザーの課題解決を優先します。
タグ・特集・比較ページ:価値基準とnoindex判断
意図の明確さと差別化(独自データ・編集観点)が基準に達するページのみindexし、未満はnoindexで管理します。比較は評価軸の明確化と更新フローを運用化し、陳腐化の早い要素の更新責任を明確にします。ハブとして外部リンクを取りに行ける編集企画に昇華できるかを判断ラインとし、中途半端な集合乱立は避けます。
トラブルシューティング(よくある失敗と対処)
「検出-インデックス未登録」の大量発生はクロール不足・品質不足・ブロック誤りを切り分けます。canonical/noindexの矛盾やサイトマップ不整合は優先是正です。
「検出-インデックス未登録」が大量発生するケース
重要URLへのクロール不足(導線/サイトマップ不足)、薄い一覧や重複詳細による品質問題、noindex/robots設定の誤りが典型です。まずログで必要:不要クロール比を正し、サイトマップと内部リンクで発見性を改善し、それでも未登録が残る集合に品質改善を投入します。GSCの到達率とログ頻度の両輪で、どこがボトルネックかを定量で把握します。
canonicalとnoindexの衝突/自己カノニカル漏れ
noindexとcanonicalの併用は矛盾ですべて解消し、全ページで自己カノニカルを徹底します。内部リンクとサイトマップは正規URLへ統一し、ブラウザで到達し得る非正規URL(大文字小文字、末尾スラッシュ差異等)は301で集約します。信号の不一致はGoogleの解釈を不安定化させるため、最優先で整流化します。
サイトマップURLの整合性エラー・更新停滞
50,000URL/50MB制限を遵守し、lastmodを更新、noindex/除外URLを含めないのが基本です。タイプ別に分割し、sitemap indexで管理します。フェッチ失敗や古いURLの残留は到達率を悪化させるため、生成ジョブの監視と失敗通知、定期の完全再生成を運用に組み込みます。
参考: https://developers.google.com/search/docs/crawling-indexing/sitemaps/build-sitemap 、https://developers.google.com/search/docs/crawling-indexing/sitemaps/large-sitemaps
内部検索結果がインデックスされてしまう問題
内部検索は原則noindexとし、検索結果へのリンク露出を削減するUI改修を優先します。需要が大きいトップクエリのみ編集・固定化した専用ランディングを作り、そこで初めてindex対象とします。robotsだけでなく、内部リンクとサイトマップに検索結果URLを含めない運用を徹底します。
よくある質問(FAQ)
インデックス数が増えないのはなぜ?何から直す?
ログで必要:不要クロール比を是正し、サイトマップ/内部リンクで発見性を上げ、それでも残る未登録集合に品質改善を投下する順番が効率的です。
参考: https://ny-marketing.co.jp/blog/crawl/crawler_analyze/
パラメータ付きURLは全部noindexにすべき?
ソート/件数/トラッキングはnoindex推奨ですが、需要×件数が十分な代表ファセットはcanonicalで正規化しつつindexも検討します。無限生成はrobots.txtで抑え、内部リンクで付与しないテンプレ運用が肝です。
内部検索結果ページはindex対象?
原則noindexです。編集・固定化して独自価値を持つトップクエリのみ例外的にindex対象とします。
サイトマップは何ファイルに分ける?更新頻度は?
1ファイル50,000URL/50MB以内が上限。タイプ/言語で分割し、更新の多い集合は高頻度でlastmodを反映します。
ページネーションの最適解は?
各ページ自己カノニカル、noindex/nofollowは非推奨。HTMLで前後リンクを明示し、代表一覧からの導線を整えます。参考: https://searchengineland.com/pagination-seo-what-you-need-to-know-453707
ファセット(絞り込み)ページのインデックス方針は?
需要×件数が十分な代表のみindexし、複合・末端はnoindex+canonicalで代表へ寄せます。
在庫切れ・募集終了ページは削除/リダイレクト/放置のどれ?
恒久終了+代替有は301、代替薄いは存置+代替提案+構造化更新、一時欠品は存置で構造化に反映します。
Search Consoleのカバレッジで見るべきKPIは?
有効/除外推移、「検出-未登録」の減少、意図的noindex比率、サイトマップ到達率です。
サーバーログ分析で何が分かる?実装のハードルは?
不要パラメータ・静的資産への過剰、重要URLの不足、5xx/404などがわかります。10万P超では月次運用が必須です。
事例とベンチマーク(要点のみ)
10万ページ超のDB型サイトでのクロール最適化→インデックス改善の流れ
ログで不要クロール比を特定し、robots・導線・サイトマップを同時に修正。結果として重要URLのクロール頻度が増加し、GSCの「検出-未登録」が減少。有効ページ増とともに自然検索アクセスが10%改善した社内実績があります。重要なのは一度きりでなく6カ月の継続です。
https://www.youtube.com/watch?v=1ccWY5ogJPA
内部リンク再設計で評価循環を回しCTRも改善したケース
ハブ強化と関連/人気導線の再配置で回遊が上がり、クロール頻度の増加→CTR/順位の上昇という好循環が生まれました。加えてタイトルの前方語最適化を合わせ、一覧CTRが継続的に改善。テンプレに勝ちパターンを展開したことで、長尾集合にも波及効果が出ました。
まとめ:DB型サイトSEOは「設計と運用の勝ち筋」を仕組み化する
勝ち筋は「クロール最適化→インデックス確実化→評価循環(内部リンク/構造化/タイトル)」の順序です。設計(IA/URL/テンプレ)と運用(ログ/カバレッジ/ABテスト)を月次で継続し、テンプレで勝ちパターンを全ページに波及させます。
記事の要点サマリーと次の一手
まずログで不要クロールを削減し、サイトマップと内部リンクで重要URLの発見性を最大化します。ファセット、ページネーション、在庫終了の運用ルールをテンプレ化し、構造化データとタイトルCTR最適化を全ページ型へ展開します。6カ月の改善サイクルで成果が雪だるま式に増えます。
当社の支援について(DB型サイト特化SEO/クロール分析の初回相談)
当社は生ログ解析×サイトマップ×内部リンクの三位一体で「クロール→インデックス→成長」を設計します。10万ページ超のDB型で豊富な支援実績があり、初回相談を無料でご提供可能です。社内ツールと運用ダッシュボードで月次の改善サイクルを伴走します。