
robots.txtとは、クローラーに対してアクセスの制限をするためのテキストファイルです。
robots.txtを設定することで、クローラーの動きをコントロールできます。これにより、クロール効率を高め、サイト全体のSEOに良い影響を与えることができます。
ただし、robots.txtを設置する際には注意しなければいけないことがいくつかあります。
本記事では、弊社NYマーケティングの代表中川が0から月間1億PVのサイト成長を達成した実績と14年間の経験をもとに、robots.txtの設置方法や設置の際の注意点などを詳しく解説します。
>>>全16項目で完全解説!SEO内部対策大全をダウンロードする
robots.txtやクロール設定、間違っていませんか。
「なぜか検索順位が上がらない…」「インデックスされない記事がある…」そんな悩みは、内部対策のミスが原因かもしれません。
SEOスポット調査 × 内部対策代行なら、
✔ 正しいrobots.txtの構文チェック
✔ noindexやcanonicalの誤設定診断
✔ クローラビリティ改善のアドバイス
を【一括で分析&提案】します。

robots.txtとは
robots.txtは、検索エンジンのクローラーに対してサイト内のどのページにアクセスしてよいかを伝えるためのテキストファイルです。
robots.txtでクロールしなくてもよいページを指定することで、重要なページを優先的にクロールしてくれます。
robots.txtは必須ではない
robots.txtの主な目的としては、クロールをブロックするために使用することが多く、クロールを拒否したいページが無い場合は、設置しなくても特段問題ありません。
大規模サイトになるとrobots.txtの制御が必要
ページ数が多くないサイトは、robots.txtを設置しなくても特段問題ありません。しかし、データベース型サイトやECサイトのような、サイト規模が大きいサイトはrobots.txtによる制御が必要になります。
なぜなら、ページ数の多い大規模サイトではクロールバジェットの最適化が必要になるからです。
クロールバジェットとは、クローラーが特定期間内にサイトに対してクロールする、リソースのことです。
クローラーにクロールバジェットがある以上、大規模サイトでは全てのページをクロールしてもらうことは不可能になってきます。そのため、「重要度の低いページはクロールさせない」などのクロール制御をし、クロールを最適化する必要があります。
クロールバジェットについて詳しく知りたい方は、以下の記事を参考にしてください。

robots.txtの書き方と見方
robots.txt は次のような書式のテキストファイルです。テキストエディタで作成することができます。
User-agent: *
Disallow: /example/
Allow: /example/public/
Sitemap: https://www.example.com/sitemap.xml以下でそれぞれの項目を解説します。
>>>全16項目で完全解説!SEO内部対策大全をダウンロードする
user-agent
user-agentでは、クローラーの種類を指定できます。robots.txtを設定する場合は、user-agentの指定が必須になります。
例えば、User-agent: *を指定すると、全てのクローラーが対象となります。通常、ほとんどのサイトではUser-agent: *の指定で問題ありません。特定のクローラーを指定する場合は以下のように記述します。
| 記述例 | 意味 |
|---|---|
User-agent: Googlebot | Googleのクローラーのみを対象とします |
User-agent: Googlebot-Image | Google画像検索用のクローラーのみを対象とします |
例えば、以下のようにして、後述するdisallowとともに活用します。
▼Googlebotからの特定のディレクトリをクロール拒否したい場合
(以下の例では、exampleディレクトリのクロールをブロック)User-agent: Googlebot
Disallow: /example
▼全てのクローラーを対象に、特定のディレクトリをクロール拒否したい場合
(以下の例では、exampleディレクトリのクロールをブロック)User-agent: *
Disallow: /example
disallow
disallowでは、クロールを拒否したいディレクトリ・ページを指定できます。
robots.txtのデフォルトでは全URL「許可」なので、disallowで指定していないURLは全てクロールが許可されます。
Disallow: /example/とすると/example/ ディレクトリ配下の全てのURLのクロールを拒否できます。また、Disallow: /*.mp4やDisallow: /example/$のように拡張子ごとの指定や完全一致での指定など細かく設定することも可能です。
| 記述例 | 意味 |
|---|---|
Disallow: / | すべてのURLを拒否します |
Disallow: /example/ | /example/ ディレクトリ配下のページを拒否します |
Disallow: /*.mp4$ | ファイル拡張子がmp4のファイルをすべて拒否します |
Disallow: /example/$ | /example/ に完全一致するURLのみを拒否します |
disallowでの指定方法はGoogle検索セントラルのrobots.txt の書き方、設定と送信に詳しく記載されていますので、ご参照ください。
allow
allowはクロールを許可するページを指定することができます。allowはわざわざ書かなくてもデフォルトがクロール許可となるので、使う機会が少ないのが現状です。
しかし、allowはdisallowよりも強い権限を持っているため、disallowで拒否したURLパスの一部を許可するときに役立ちます。そのため、allowはdisallowとセットで使用します。
| 記述例 | 意味 |
|---|---|
Disallow: /example/ | /example/ディレクトリを拒否します ※ただし、/example/public/ディレクトリのみ許可します |
Disallow: /example/ | /example/ディレクトリを拒否します ※ただし、mp4のファイルのみ許可します |
sitemap
sitemapはクローラーにウェブサイトのXMLサイトマップの場所を知らせるために使用します。
sitemapは必ず記載する必要はありませんが、sitemapを適切に記述しておけば、クローラーがXMLファイルを積極的に読み、効率の良いクロールを行ってもらえます。
sitemapは以下のようにsitemap.xmlのファイルパスまでを絶対パスで記述します。
Sitemap: https://www.example.com/sitemap.xmlrobots.txtとXMLサイトマップの関係性について詳しく知りたい方は、以下の記事を参考にしてください。

robots.txtやクロール設定、間違っていませんか。
「なぜか検索順位が上がらない…」「インデックスされない記事がある…」そんな悩みは、内部対策のミスが原因かもしれません。
SEOスポット調査 × 内部対策代行なら、
✔ 正しいrobots.txtの構文チェック
✔ noindexやcanonicalの誤設定診断
✔ クローラビリティ改善のアドバイス
を【一括で分析&提案】します。
robots.txtの確認方法
robots.txtが正しく設置できているかの確認は、Google Search Consoleのrobots.txtレポートで確認できます。(※2023年12月12日以前は、robots.txtテスターと呼ばれるツールを使用できましたが、現在は使用できません)
具体的には、以下のキャプチャ画像の赤枠の「設定」→「クロール」の「robots.txt」から確認できます。
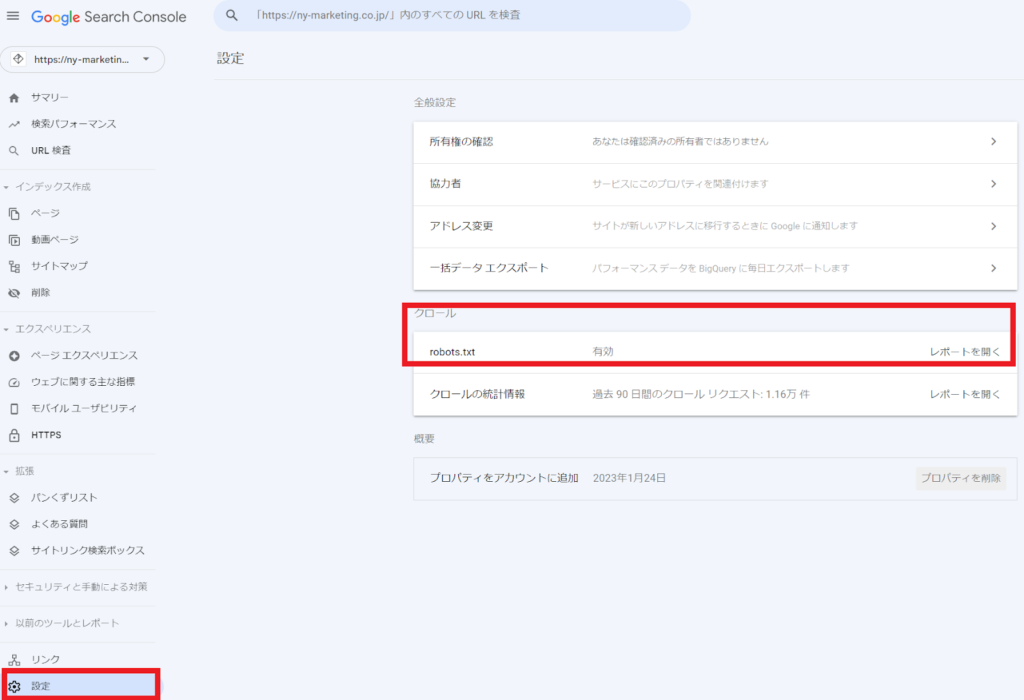
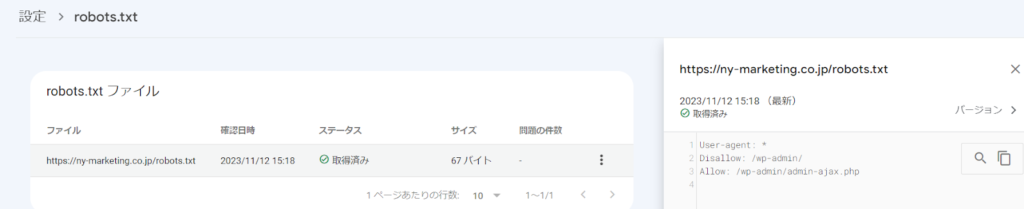
robots.txtの設定を誤ってしまうと、本来クロールされるべきページにクローラーが回ってこなくなります。SEOに大きな悪影響を及ぼすため、要注意です。robots.txtを設定した後は必ず、Google Search Consoleのrobots.txtレポートで確認しましょう。
参照:robots.txt レポート – Search Console ヘルプ
robots.txtの場所はどこに設置すべきか?
robots.txtファイルは、サイトのルートディレクトリに設置する必要があります。(サブドメインに設置する場合においても同様にルートディレクトリです)
ルートディレクトリに設置することで、クローラーはサイト訪問時に最初にこのファイルを参照し、robots.txtに記載した指示を受け取ります。
例えば、弊社NYマーケティングのサイトの場合、robots.txtファイルは、
https://ny-marketing.co.jp/robots.txtとなっております。
実際に上記のURLの中身を見てみると、以下のキャプチャ画像のようにrobots.txtが記載されていることが分かります。
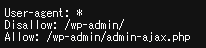
また、サブドメインにrobots.txtを設置する場合においても同様に、以下の通り、ルートディレクトリに設置します。
https://sub.ny-marketing.co.jp/robots.txt参照:「robots.txt ファイルを確認する」robots.txt レポート – Search Console ヘルプ
robots.txtやクロール設定、間違っていませんか。
「なぜか検索順位が上がらない…」「インデックスされない記事がある…」そんな悩みは、内部対策のミスが原因かもしれません。
SEOスポット調査 × 内部対策代行なら、
✔ 正しいrobots.txtの構文チェック
✔ noindexやcanonicalの誤設定診断
✔ クローラビリティ改善のアドバイス
を【一括で分析&提案】します。
robots.txtのSEO効果は大きく2つ
SEOの観点から見ると、robots.txtを設定することには大きく2つの効果があります。
>>>全16項目で完全解説!SEO内部対策大全をダウンロードする
重要度の高いページを優先的にクロールしてくれる
先ほどの「大規模サイトになるとrobots.txtの制御が必要」の項で説明したように、クローラーにはクロールバジェットが存在します。つまり、クローラーがクロールできるリソースには限界があります。
robots.txtを使用することで、クロールさせないコンテンツの指定ができます。これにより、重要なコンテンツを優先的にクロールさせることが可能となります。
検索エンジンが重要なコンテンツを素早く発見し、インデックス登録することで、ユーザーにとって有益な情報を迅速に提供することができます。結果として、サイト全体が高い評価を受けやすくなります。
クロールされる必要のないページをクロールさせない
robots.txtを使用することで、低品質なコンテンツや、クローラーに読み込ませたくないページのクロールを制御できます。
クローラーに価値のあるページだけをクロールしてもらい、評価対象とすることで、検索エンジンがサイト全体を有益なコンテンツとみなし、高い評価を受けます。この傾向は、最近のGoogleのヘルプフルコンテンツシステムのアップデートで顕著になっています。
robots.txtに関する注意点4つ
robots.txtは誤って使用すると、サイトに悪影響を及ぼす可能性があるため注意が必要です。以下の4つの点に注意して使用してください。
記述をミスするとクロールされない
robots.txtファイルに誤った記述をすると、重要なコンテンツがクロールされなくなる可能性があります。1文字のミスで検索流入の大半を失うこともあるため、注意が必要です。
必ず、アップロードした後にGoogle Search Consoleのrobots.txtレポートを確認し、誤った設定・記述をしていないか確認しましょう。
robots.txtを指定してもユーザーはアクセスできる
ユーザーのアクセスブロックを目的として、robots.txtのdisallowでクロール拒否の設定をしたとしても、ユーザーはそのURLを入力すればアクセスできてしまいます。そのため、ユーザーからのアクセスを禁止したい場合は、basic認証などのパスワード保護を使用しましょう。
テスト環境でのrobots.txtの指定は要注意
テスト環境でのサイト構築時にrobots.txtでdisallowを設定している場合、本番環境に反映した時に引き継いでいないか注意が必要です。
本番環境に反映した後は必ず、robots.txtの設定を一度確認しましょう。robots.txtレポートで確認するようにしてください。
検索結果から削除をしたい場合は、robots.txt以外の対応も必要
検索結果からページを削除したい場合に、robots.txtのdisallowの設定をしたとしても、検索結果上に残る可能性があるので注意が必要です。
検索結果から直ちに消去したい場合は、Google Search Consoleの削除ツールを使用しましょう。
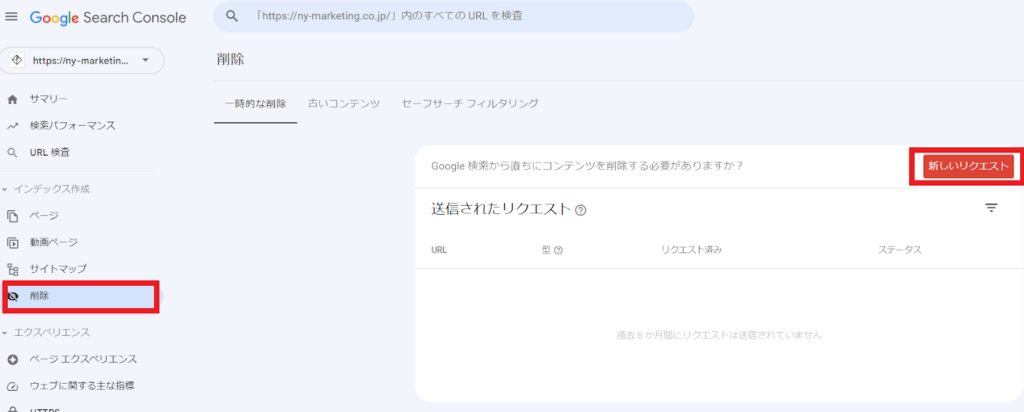
ただし、削除ツールは一時的に検索結果に表示しないだけです。根本的な対処としてはページ削除やnoindexといった対処が必要になります。
robots.txtやクロール設定、間違っていませんか。
「なぜか検索順位が上がらない…」「インデックスされない記事がある…」そんな悩みは、内部対策のミスが原因かもしれません。
SEOスポット調査 × 内部対策代行なら、
✔ 正しいrobots.txtの構文チェック
✔ noindexやcanonicalの誤設定診断
✔ クローラビリティ改善のアドバイス
を【一括で分析&提案】します。
robots.txtに関してよくある質問
最後に、robots.txtに関してよくある質問とその解説を2つ紹介します。
>>>全16項目で完全解説!SEO内部対策大全をダウンロードする
「robots.txt によりブロックされました」とはどのような状態か?
Google Search Consoleで「robots.txtによってブロックされました」と検出されている事象は、robots.txtファイルによって特定のURLがクロールされていない状態を指します。この状態では、GoogleのクローラーがそのURLをクロールできないため、検索結果に表示されない可能性が高くなります。
もしも、該当URLをクロールされたいにも関わらず「robots.txtによりブロックされました」と表示されている場合、そのURLに対してrobots.txtのdisallowが誤って設定されていないかを確認しましょう。設定が誤っていた場合は直ちに修正する必要があります。
robots.txtとnoindexの違い、使い分け方
robots.txtがクローラーのアクセスを制御するのに対し、noindexはページの検索結果へのインデックス登録を制御します。robots.txtとnoindexは一見似ているようで、用途と目的が全く異なります。
noindexとrobots.txtの違いについて詳しく知りたい方は、以下の記事を参考にしてください。

まとめ:robots.txtの指定は慎重に【SEOの専門家への相談を推奨】
robots.txtを正しく設定すると、クロールバジェットを最適化でき、SEOに好影響を与えます。ただし、誤った設定をしてしまうと、サイトの流入を大きく落とすことにつながります。特に、大規模サイトの場合は誤った設定が大きな損失に繋がってしまい、致命的になります。
そのため、この記事を読んでもrobots.txtの設定に不安がある方は、SEOの専門家へ相談することをおすすめします。
弊社NYマーケティングはSEO歴14年のナレッジと実績があります。特に、ECサイトやポータルサイトといった大規模サイトの内部SEOを得意とし、ポータルサイトのPV数を月間1億PVまで伸ばした実績があります。
今回紹介したrobots.txtの最適化からその他のSEO課題まで、お客様にとって最適なSEO施策を提供いたします。初回無料相談を承っておりますので、下記のリンクからお気軽にお問い合わせください。
SEOスポット調査 × 内部対策代行なら、
✔ 正しいrobots.txtの構文チェック
✔ noindexやcanonicalの誤設定診断
✔ クローラビリティ改善のアドバイス
を【一括で分析&提案】します。