
robots.txtとnoindexは、「クローラーに対して働きかける」点で似ていますが、それぞれ役割が全く異なります。
特に、サイト規模が大きくなればなるほど、robots.txtとnoindexを適切に使い分けることが、内部SEO対策に好影響を与えます。しかしその反面、正しく理解せず誤って使用してしまうと、Webサイトの流入を大きく落とすことにつながるため注意が必要です。
この記事では、弊社NYマーケティングの代表中川が0から月間1億PVのサイト成長を達成した実績と14年間の豊富な経験を基にrobots.txtとnoindexの相違点とそれぞれの機能、SEO効果を高める方法について詳しく解説します。
>>> 全16項目で完全解説!SEO内部対策大全をダウンロードする
SEO評価を落とすnoindex・クロール設定…放置していませんか。正しいインデックス管理ができていないと、良質なコンテンツも評価されません。「内部対策代行」でサイト構造を根本から最適化し、正しい設定とSEO成果を両立しませんか?

robots.txtとnoindexの違い
robots.txtとnoindexは、共に検索エンジンの動作を指示する点で共通しています。しかし、この2つは役割が異なります。
robots.txtは「クローラーのクロールを制御する」役割がありますが、noindexの役割は「クローラーのインデックス登録を制御する」になります。
robots.txtとは|クロールをブロックできる
robots.txtとはクローラーに対して、サイト内のどのディレクトリ・URLにアクセスしてよいかを伝えることができるファイルのことです。
そもそも、検索エンジンが各サイトのデータを収集する際には、クローラーと呼ばれる自動巡回プログラムがウェブページを訪れて情報を収集し、そのデータに基づきサイトが検索エンジンに認識されます。
しかし、サイトごとにクロールできるページ数には制限があります。(このことをクロールバジェットといいます)そこで、robots.txtを利用して不要なコンテンツのクロールを制限し、クローラーによる重要なページのクロールを促進させます。
このクロールの制限により、クローラーがクロールして欲しい重要なページを、優先的にクロールしてくれるようになります。

noindexとは|インデックスから除外できる
noindexは、特定のページが検索エンジンにインデックスされないよう、検索エンジンに伝えるマークアップタグのことです。
サイト内に低品質なページや類似するコンテンツがある場合、それらのページがクロールされると、検索エンジンからの評価が下がります。
それだけでなく、ヘルプフルコンテンツシステムのアップデートにより、それらの低品質と捉えられるページが存在した場合、サイト全体の評価を損ない、高品質なページの評価をも引き下げてしまう可能性があります。
noindexタグを記述して、インデックスさせるべきでないページをインデックスさせないことで、検索順位に悪影響を及ぼすことを避けられます。

robots.txtとnoindexの使い分け
robots.txtとnoindexは使い方が全く異なります。以下でそれぞれの使い方を解説します。
robots.txtを使う場面
robots.txtは主に、
- クローラーのアクセスを拒否したい時(例:会員制ページや開発中のページなど)
- クロールバジェットを最適化したい時(クロール効率の最適化)
などに使用します。
また、robots.txtファイル内にXMLサイトマップのパスを記述することで、XMLサイトマップの存在をクローラーに提示できます。
robots.txtとXMLサイトマップの関係性について詳しく知りたい方は、以下の記事を参考にしてください。

noindexを使う場面
noindexタグは、検索エンジンに特定のページを検索結果に表示させないよう指示するために使用します。
使用される場面として多いのは、サイト内に類似するページがある場合や、検索エンジンから低品質と捉えられるページが存在する時などです。
検索エンジンは、サイト内に類似するページが存在する場合に重複コンテンツと捉え、また低品質と捉えるコンテンツが存在する場合に、そのサイト全体の評価を下げます。
そのため、noindexタグを適切に設置することは、「サイトの評価をプラスにする施策」というよりは、「サイトがマイナス評価になることを防ぐための施策」といった側面の方が強いです。
【補足情報】noindexとnofollowの違い
noindexタグは、クローラーに対し、特定のページをインデックスしないように指示を出します。これは、ページ自体はクローラーによって読み込まれる可能性があるものの、そのページが検索結果には表示されないようにするためのものです。
これに対してnofollowタグは、クローラーに対し、リンク元の評価をリンク先へ受け渡さないように指示します。
noindexはページ自体が検索結果に出ないようにするためのもので、nofollowはリンクを通じて他ページへ評価を渡さないようにするもので、使用目的が全く異なります。
noindexとnofollowの違いについてさらに詳しく知りたい方は、以下の動画をご覧ください。
noindex・クロール制御のミスは“機会損失”です。知らぬ間に重要ページがGoogleに評価されていないかもしれません。専門チームによる「内部対策代行」で、設定漏れ・重複・クロール指示を一括改善しましょう。
robots.txtの書き方
robots.txtを設置する場合は下記の4種類の記述方法から構成され、必要に応じて記述し指定していきます。
- disallow
- allow
- sitemap
- user-agent
下記でそれぞれ詳しく解説します。
>>> 全16項目で完全解説!SEO内部対策大全をダウンロードする
robots.txtの基本の書き方
まずrobots.txtの初期の設定として、特定のディレクトリ・ページへのクロールを制御する必要が無い場合は、以下の記述をします。
User-Agent: *
Disallow:
Sitemap: http://example.com/sitemap.xml※robots.txtファイルの設置と記述は必須ではないため、上記はあくまでrobots.txtを設置する場合の初期設定と捉えてください。
上記のように記述し、「/robots.txt」のファイル名で保存します。その後、必要な指示を記述した後、ウェブサーバーにアップロードします。
このようにrobots.txtファイルを作成するには、新規テキストファイル(ファイル名は基本的に「robots.txt」)に必要なコードを記述してサーバーにアップします。
disallowでクロールをブロックする
disallowとは、クローラーのアクセス制限を指定する記述です。クロールしてほしくないファイルやディレクトリをdisallowで指定することによって、クロールがブロックされます。
一方で、disallowが空欄になっている場合は、いずれのファイルやディレクトリに対してもクロールの制限を行わないことになります。
クロールを制限するには、disallowを使ってクロール拒否したいページやディレクトリのパスを記述する形になります。
User-Agent:*
Disallow: /example/この例では、/example/ ディレクトリ内のすべてのページやファイルが、クローラーによるクロールをブロックしています。
このように、disallowにファイル名を記述して、ページやディレクトリを絞り込むことでクロール制限したいファイルが限定できます。
ただし、disallowの指定を誤ると、該当のページ・ディレクトリに全くクロールされなくなるため、指定には注意が必要です。不安な場合は、SEOの専門家に相談しましょう。
allowでクロールを許可する
allowによってクロールを許可するページを指定することができます。allowはわざわざ書かなくてもデフォルトがクロール許可となるので、使う機会が少ないのが現状です。
しかし、allowはdisallowよりも強い権限を持っているため、すでにdisallowを使っているけれど、特定のページやディレクトリだけクロール許可したい場合にallowを指定します。
User-agent: *
Disallow: /example/
Allow: /example/sample.htmlこの設定では、/example/ディレクトリ内の全てのファイルがクロールから除外されますが、例外として、/example/sample.htmlのみクロールが許可されています。
このように、allowにページやディレクトリのパスを記述して、特定のページ・ディレクトリのみクロールを許可することができます。
sitemapでクロールを効率化する
sitemapは、クローラーにウェブサイトのXMLサイトマップの場所を知らせるために使用されます。
XMLサイトマップとは、クロールして欲しいURLのリストをまとめたXML形式のファイルのことであり、クローラーはこれによってクロールを行う優先度を決めています。
sitemapを適切に記述しておけば、クローラーがXMLファイルを積極的に読み、効率の良いクロールを行ってもらえます。
XMLサイトマップの場所をクローラーに知らせる場合は、以下のように「Sitemap」にサイトマップのパスを記述することで、XMLサイトマップの存在を示し、クロールを促すことができます。XMLサイトマップが複数ある場合には改行して記述しましょう。
User-Agent:*
Disallow:
Sitemap: https://example.com/sitemap.xmlまた、sitemapの記述をした後は、Google Search Consoleを通じてサイトマップを登録することを忘れないようにしましょう。
robots.txtとXMLサイトマップの関係性について詳しく知りたい方は、以下の記事を参考にしてください。
user-agentで指定のクローラーを制御する
user-agentでは、特定の検索エンジンのクローラーを指定して、その動きを制御することができます。
クローラーにはGoogleのGooglebotだけでなく、BingのBingbotやBaiduのBaiduspiderなど、異なるクローラーが存在します。
通常、ウェブサイトは全てのクローラーに対してアクセスを許可しますが、user-agentを指定することで、特定のクローラーに対して制限をかけることができます。
User-agent: Googlebot-Mobile
Disallow: /example/
User-agent: *
Allow: /上記の記述では、Googleモバイル用クローラー「Googlebot-Mobile」にだけ /example/ ディレクトリへのアクセスを制限し、他のクローラーはサイトのすべてのページにアクセスできるようにしています。
参照:robots.txt の書き方、設定と送信 │ Google検索セントラル
noindexの書き方
noindexを設定する基本的な方法は、HTMLドキュメントの<head>タグにメタタグを追加する方法です。記述方法は次の通りです。
<meta name="robots" content="noindex" />noindexは上記のように、HTMLドキュメントに直接記述するのが一般的です。しかし、PDFや画像などの一部のファイルは、HTMLタグを使用することができません。このような場合は、HTTPレスポンスヘッダーに以下の記述をします。
HTTP/1.1 200 OK
(...)
X-Robots-Tag: noindex
(...)参照:noindex を使用してコンテンツをインデックスから除外する │ Google検索セントラル
robots.txtとnoindexの確認方法
ここでは、robots.txtとnoindexを記述した後、それらがGoogleから正しく認識されているかを確認する方法として、Google Search Consoleを使った確認方法を解説します。
robots.txtの確認方法
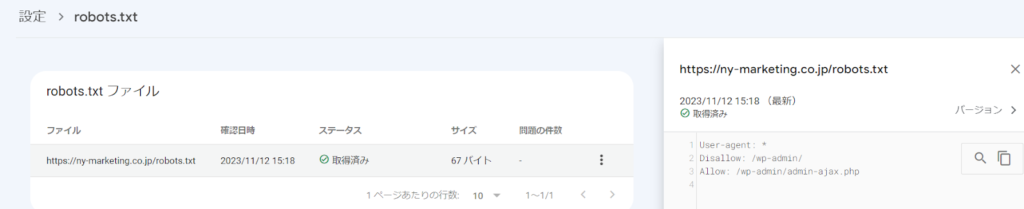
robots.txtファイルは、Googleが提供しているrobots.txt テスターを使うことで、適切に設定されているかどうか確認できます。
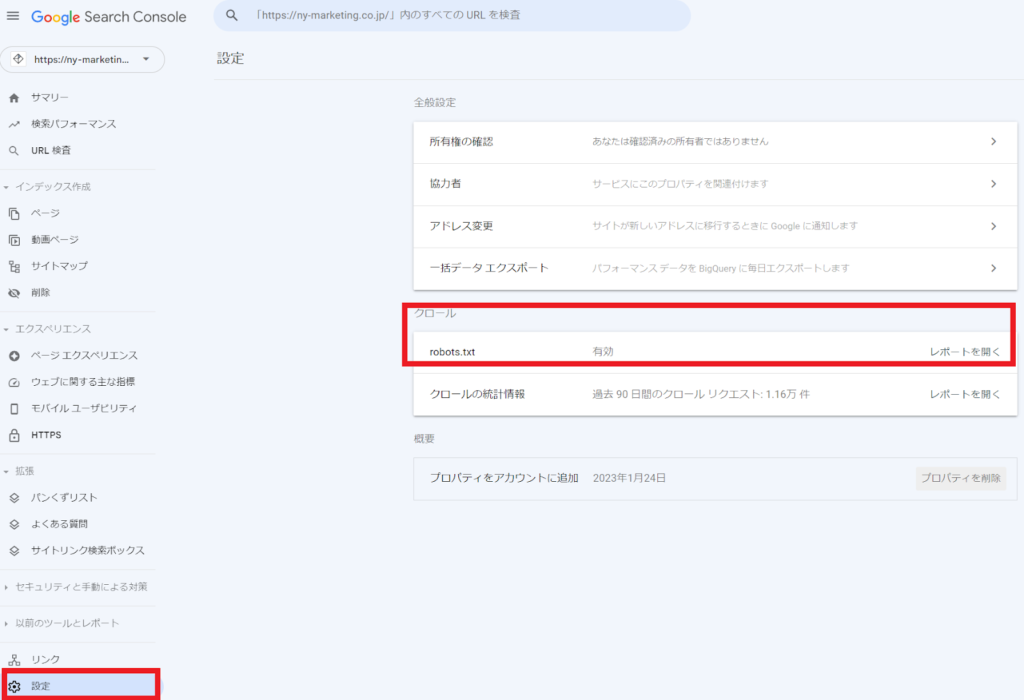
しかし、robots.txtテスターは2023年12月12日以降は利用できなくなり、代わりにGoogle Search Consoleの新しいrobots.txtレポートで確認できるようになります。具体的には、以下のキャプチャ画像の赤枠の「設定」→「クロール」の「robots.txt」から確認できます。
noindexの確認方法
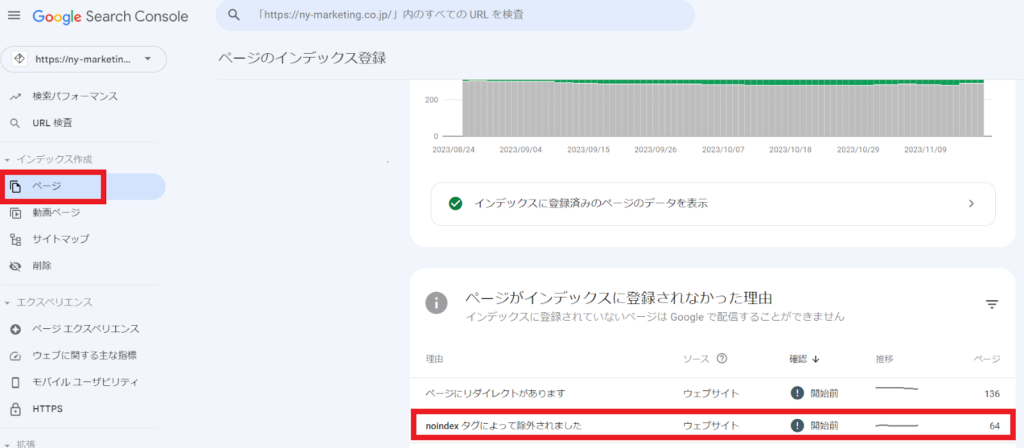
noindexタグがGoogleに正しく認識されているかは、Google Search Consoleの「インデックス作成」の「ページ」をクリックした後の「noindexタグによって除外されました」から確認できます。
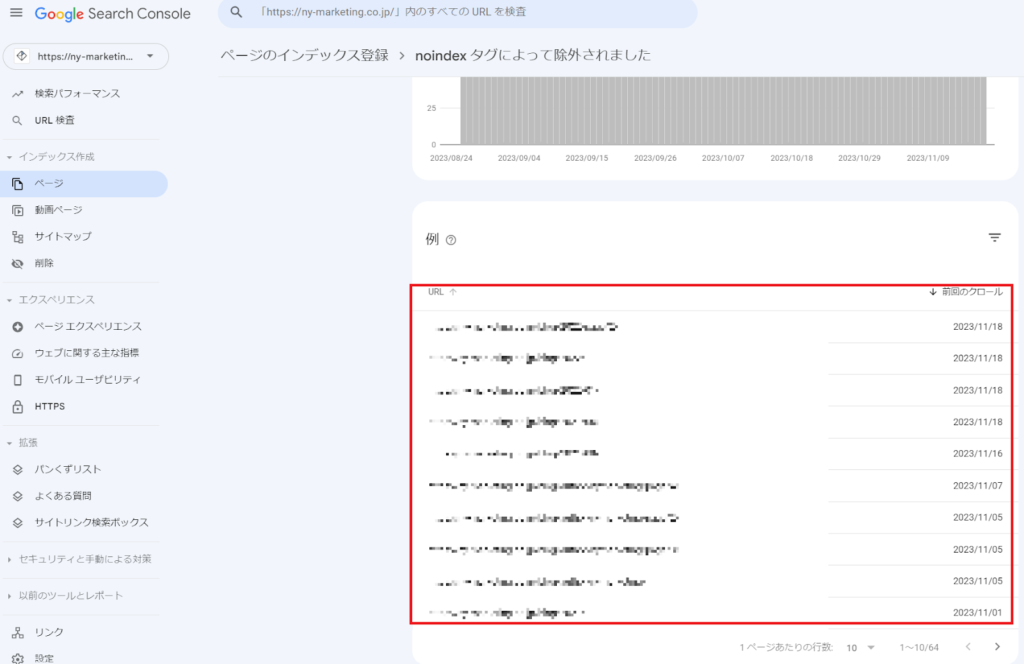
上記のキャプチャ画像のURL一覧を確認することで、サイト内のURLで、noindexさせたいURLがクローラーに対して認識されているかどうか確認できます。
robots.txtとnoindexを使う際の注意点4つ
robots.txtとnoindexは誤って使用すると、自サイトに悪影響を及ぼすので注意が必要です。以下の4つの点に注意して使用してください。
>>> 全16項目で完全解説!SEO内部対策大全をダウンロードする
robots.txtとnoindexの併用について
robots.txtでページをブロックしている場合、クローラーはそのページにアクセスすることができません。そのため、もしもnoindexでページをインデックス登録させたくない場合、robots.txtでブロックしていることが原因で、クローラーがページをクロールできずnoindexが認識されないことがあります。
この場合、robots.txtで指定をしている該当ページのrobots.txtの指定を外す必要があります。これにより、クローラーが該当ページをクロールできるようになり、クローラーにnoindexを認識させることができます。
もしも上記のrobots.txtの指定解除が難しい場合、対象ページが少ない状況においては、Google Search Consoleの「削除」を使用することでも、インデックス削除の申請ができます。(※以下のキャプチャ画像)
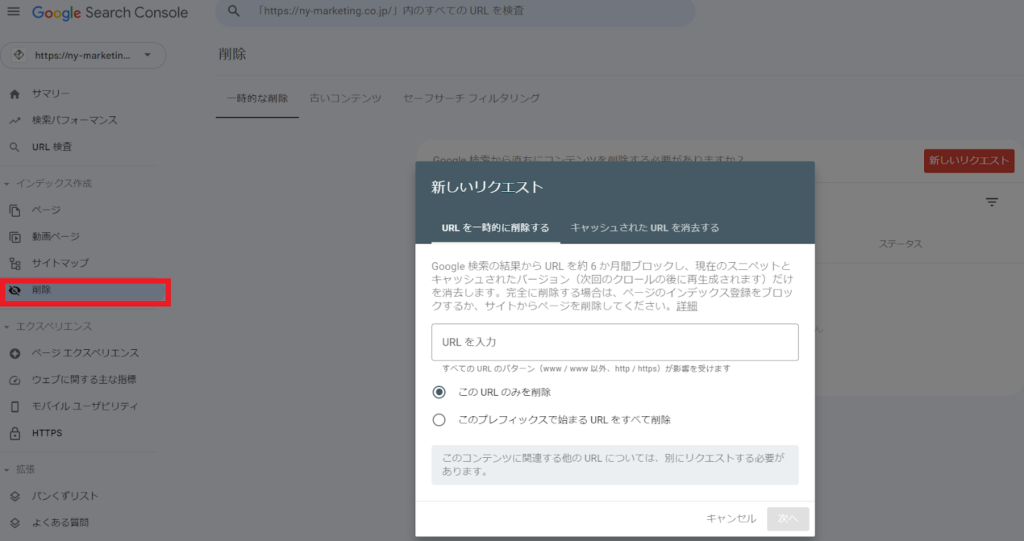
ただしGoogleの検索結果上での削除は約6か月間となるため、再び検索結果に情報が表示される可能性があることには注意が必要です。(インデックス削除として確実なのは、サーバー上からページ自体を削除することや、パスワード保護を施したアクセスのブロックです)
参考:完全に削除する │ Search Console ヘルプ
robots.txtはディレクトリの最上位に設置する
robots.txtファイルはサイトのルートディレクトリ、すなわちサイトの最上位階層に設置する必要があります。これにより、クローラーはサイト訪問時に最初にこのファイルを参照し、どのページをクロールすべきか、あるいは避けるべきかの指示を受け取ります。
例えば、
https://www.example.com/というサイトがある場合、そのrobots.txtファイルは
https://www.example.com/robots.txtとする必要があります。
実際に該当のURLを見てみると、以下のようにrobots.txtが設置されていることが分かります。

robots.txtはユーザーのアクセス制限はできない
robots.txtはクローラーへのクロール指示に用いられるもので、ウェブサイトの一般ユーザーに対してアクセスを制限する機能は持ちません。URLが公開されている限り、クロールを拒否しても、誰でもそのURLに直接アクセスできてしまいます。
そのため、サイトの特定のコンテンツへのユーザーのアクセス制限をしたい場合は、Basic認証などのパスワード保護を用いる必要があります。
robots.txtでクロール拒否してもクロールされてしまうケースがある
robots.txtファイルでブロックしている限り、クローラーは基本的にはページをクロールすることはありません。ただし、例外として、内部リンクや外部サイトからリンクを貼られている場合、リンクを通じて該当ページがクロールされてしまうことがあります。
もしも、URLが検索結果に表示されないようにしたい場合、Basic認証などのパスワード保護を施すか、一般ユーザーに閲覧させたくないページをサーバー自体から削除するなどの措置が必要になります。
SEOの伸び悩み、原因は“構造”かもしれません。検索順位が上がらないのは、noindexやrobots.txtの設定ミスかも。内部対策代行サービスで、正しいクロール&インデックス環境を構築し、評価されるサイトへ。
「robots.txtによりブロックされましたが、インデックスに登録しました」とはどのような状態か?
Google Search Consoleの「robots.txtによりブロックされましたが、インデックスに登録しました」というメッセージは、robots.txtファイルによってクローラーへのクロール拒否を指示しているページが、他のページからのリンクを通じて検索エンジンによって発見され、結果としてインデックスに登録された状況を指します。
これはnofollowが付与されていない外部リンクが存在することによって発生することがあります。これにより、ページが意図せずクロールされたことを示しています。そのため、外部サイトからのリンクによってページがインデックスされたくない場合は、該当ページにnoindexを入れる必要があります。
>>> 全16項目で完全解説!SEO内部対策大全をダウンロードする
【大規模サイト向け】robots.txtとnoindexの最適化は内部SEO対策で非常に重要
大規模サイトでは、robots.txtとnoindexを利用して適切に内部SEO対策を実施する必要があります。なぜなら、サイト規模が大きくなればなるほどページ数が増え、「どのページをクローラーに認識させて、クロールさせるか」の制御が必要になるからです。
例えば、ユーザー生成コンテンツ(UGC)のサイトにおいては、ユーザーにとっては価値あるコンテンツでも、検索エンジンが低品質と捉えてしまうものもあります。そのため、noindexを活用して、「どのページをインデックス登録させるか」や、そもそもクロールさせる必要すらないページは、robots.txtでクロールバジェットを最適化する必要があります。

このように、大規模サイトを運営する場合、クロールやインデックスを綿密に調整し、クロールされるべきコンテンツとインデックスされるべきコンテンツを適切に選別することが、SEO戦略の成功に不可欠となります。
SEOの伸び悩み、原因は“構造”かもしれません。検索順位が上がらないのは、noindexやrobots.txtの設定ミスかも。内部対策代行サービスで、正しいクロール&インデックス環境を構築し、評価されるサイトへ。
まとめ:robots.txtとnoindexを正しく使い分けてSEO効果を最大化しよう
robots.txtとnoindexの両者の違いを正しく理解し活用することは、検索エンジンにサイトの価値を正しく理解してもらうための、必須の内部SEO対策といえます。また、robots.txtとnoindexを誤って設定すると、サイトの評価が落ちるだけでなく、サイトの流入を大きく落とし売上低下にもつながるため、注意が必要です。
robots.txtとnoindexタグの使い分けを正確に実行するためには、内部SEOの専門的な知識が必要になります。
弊社NYマーケティングはSEO歴14年のナレッジと実績があります。特に、ECやポータルサイトといった大規模サイトの内部SEOを得意とし、ポータルサイトのPV数を月間1億PVまで伸ばした実績があります。
SEOの伸び悩み、原因は“構造”かもしれません。検索順位が上がらないのは、noindexやrobots.txtの設定ミスかも。内部対策代行サービスで、正しいクロール&インデックス環境を構築し、評価されるサイトへ。